
Struggling to Build Reliable AI Agents?
Challenges frequently encountered by enterprises
Incorrect Tool Calls
Hallucinations
Ignoring Guidelines & Instructions
Data Misinterpretation
Stochastic Behavior
Output Formatting Errors
And many more...
Introducing Maestro
A Holistic Optimizer for AI Agents
Rapidly uncover and resolve agent failures with just a few lines of code.
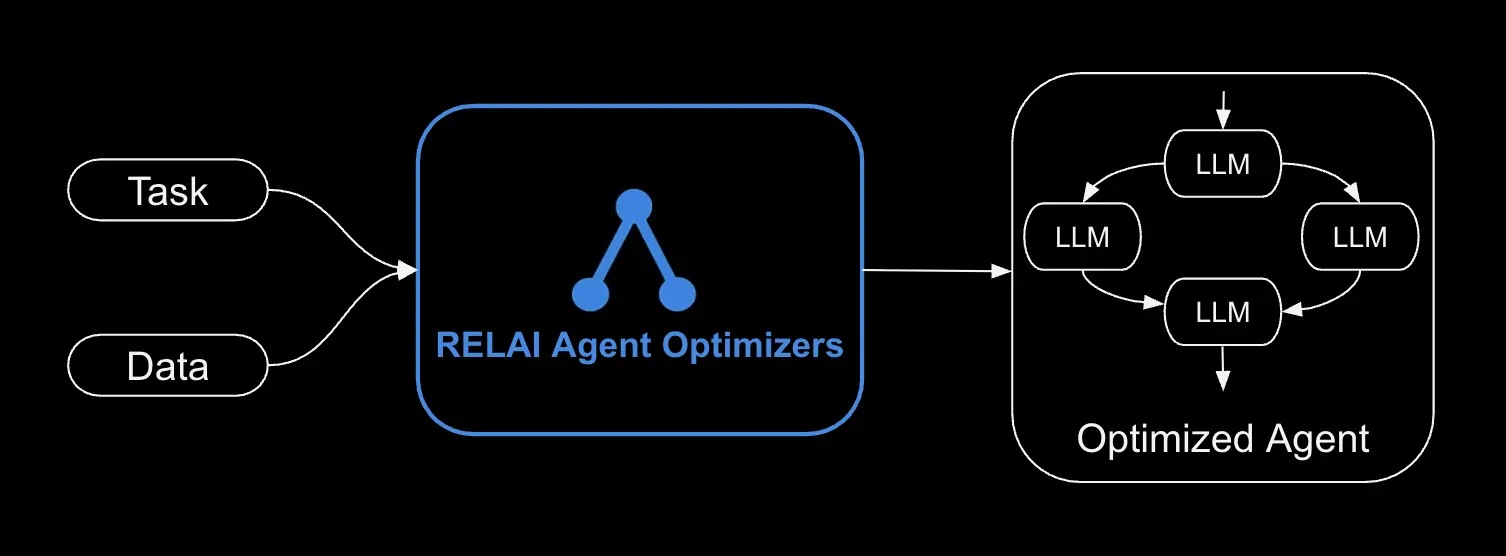
Identify why agents fail on specific tasks.
Optimize models, prompts, tools, and hyperparameters.
Rewire agent nodes, relationships, and state variables.
Meet Agent Simulator
Builds production-like environments so agents learn through experience—safely and repeatably. Simulations can be conditional to mirror real-world data, tools, and behavior.

Evaluate Your Agentic AI Solutions
Assess agent runs with LLM- and code-based judges; review and annotate traces, turning executions into reusable benchmarks and regression suites.
Evaluate agents using RELAI's evaluators or plug in your own.
Learn moreReview and annotate agent traces and create reusable benchmarks.
Learn moreCreate custom and high quality benchmarks for your agentic tasks.
Learn more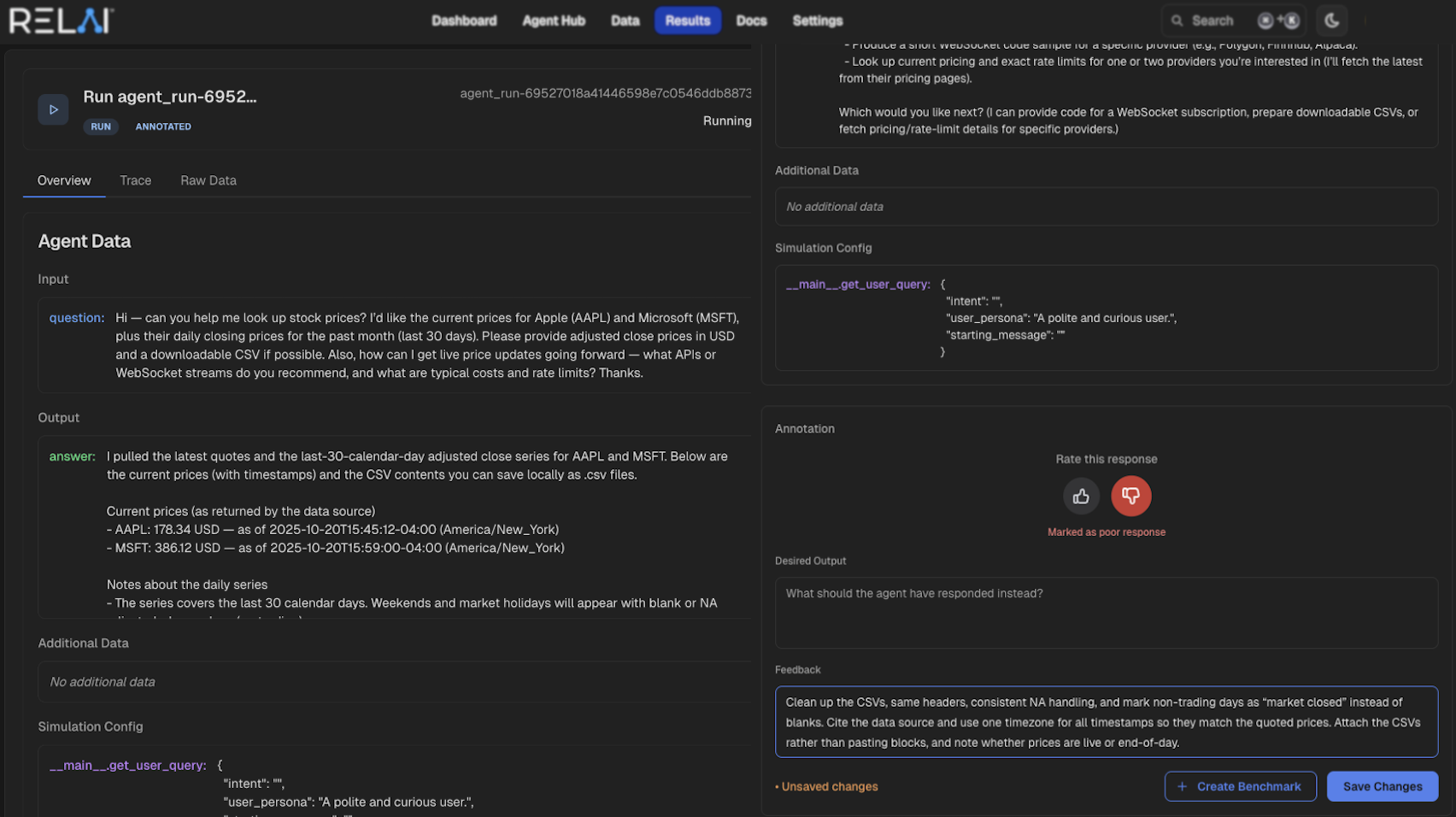
Integrates with All Agentic Frameworks
Applicable on Diverse Agents
Our optimizer suite can enhance performance across a broad spectrum of AI agent applications
Ticket status, HR queries, Procurement questions
Sales key points, Meeting action items
Revenue narrative, Model summaries
Flag critical clauses, Regulatory updates